livekitlivekit-wakeword
livekit-wakeword
livekit-wakeword is an open-source wake word detection library published by LiveKit. It ships as a Python package (livekit-wakeword on PyPI), a Rust crate (livekit-wakeword on crates.io), and a Swift package targeting iOS 16+ and macOS 14+. The library is built on top of openWakeWord's audio front-end — a frozen mel-spectrogram ONNX model followed by Google's 96-dimensional speech embedding CNN — but replaces the flat DNN classification head with a Conv-Attention head that uses 1D temporal convolutions and multi-head self-attention across 16 timesteps of speech embeddings. On the "hey livekit" benchmark (15,000 positive clips, 25 hours of audio), the conv-attention head achieves 0.08 false positives per hour and 86.1% recall, compared to 8.50 FPPH / 68.6% recall for vanilla openWakeWord — a 100× reduction in false triggers.
Showcase
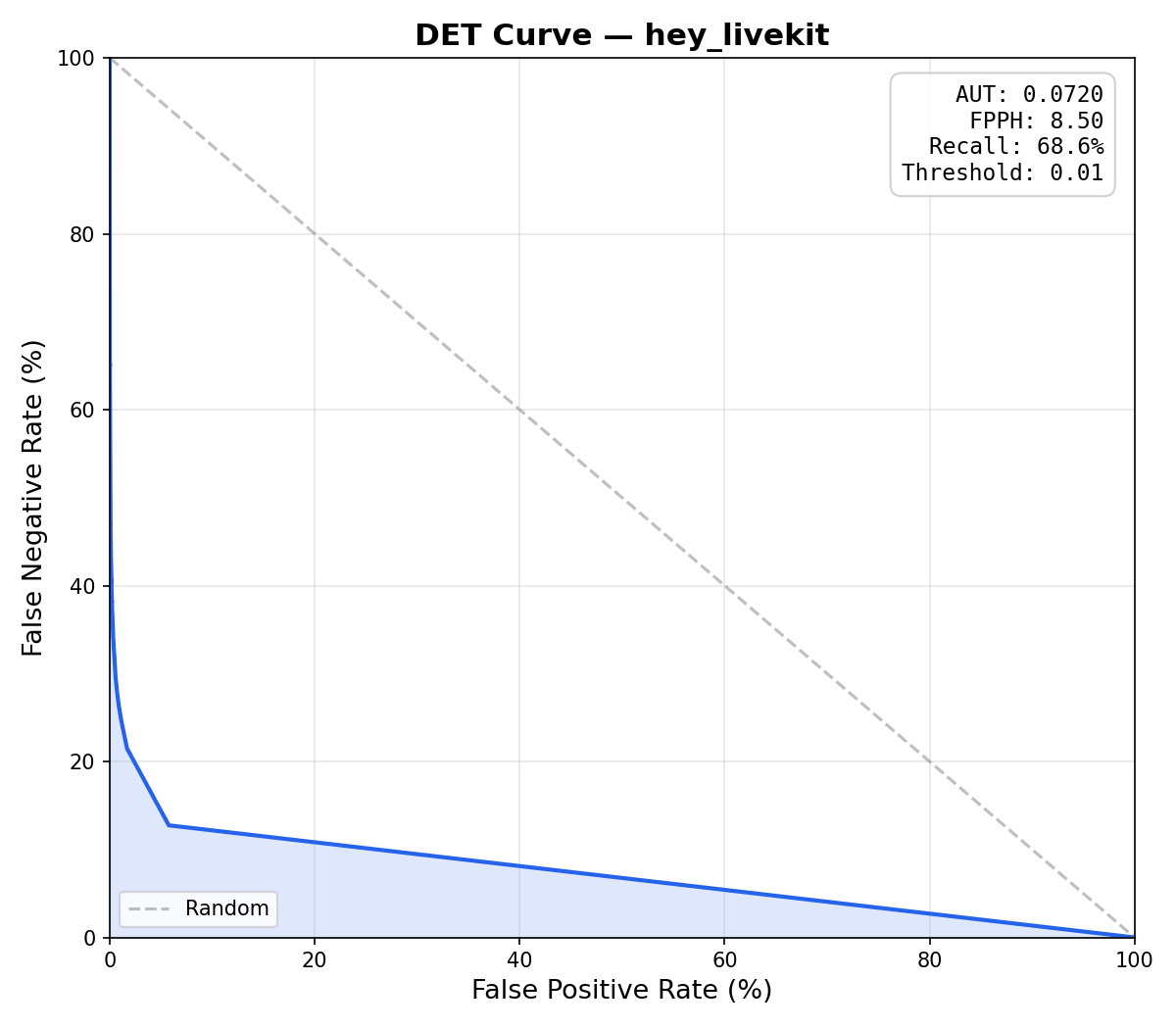
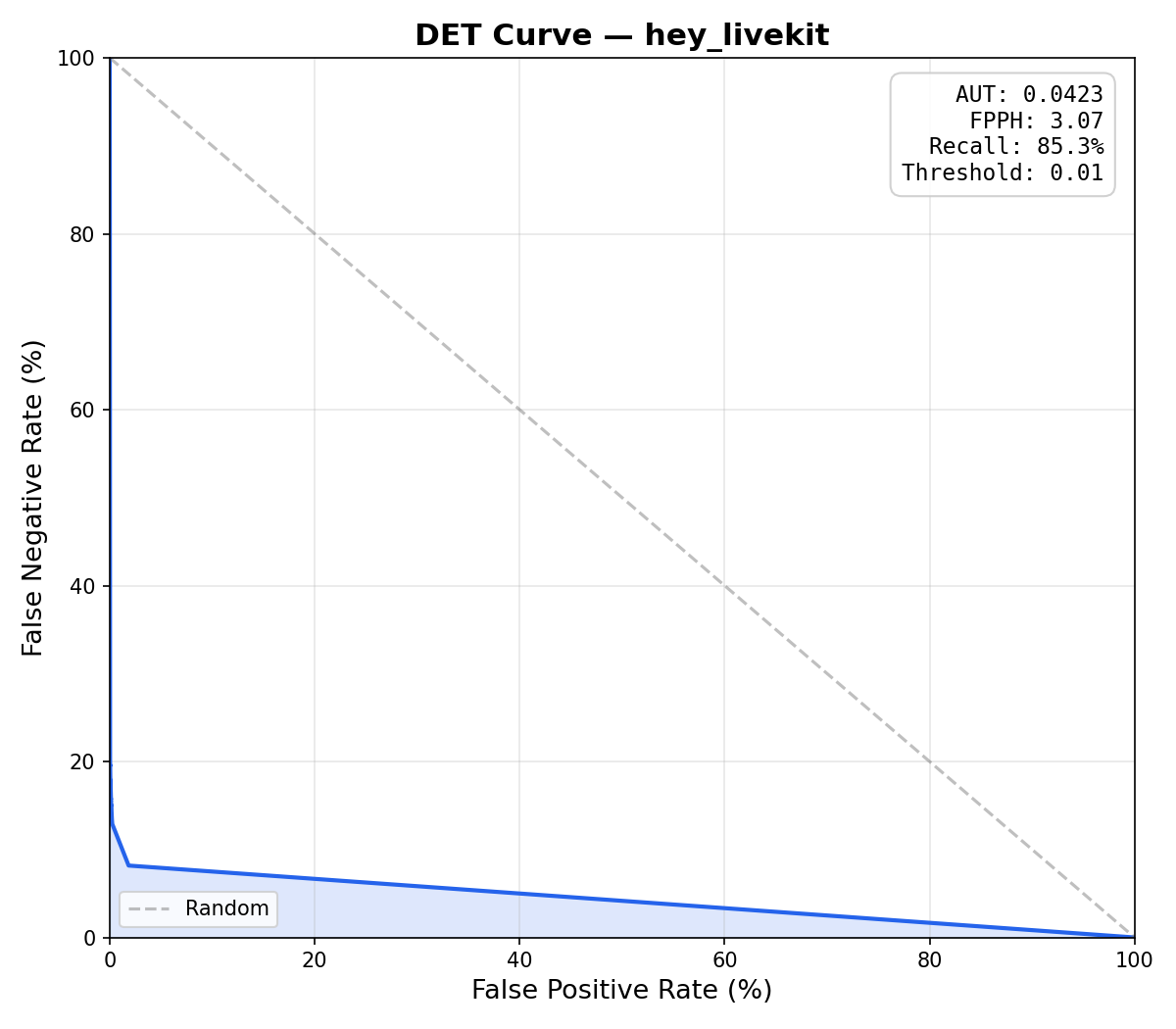
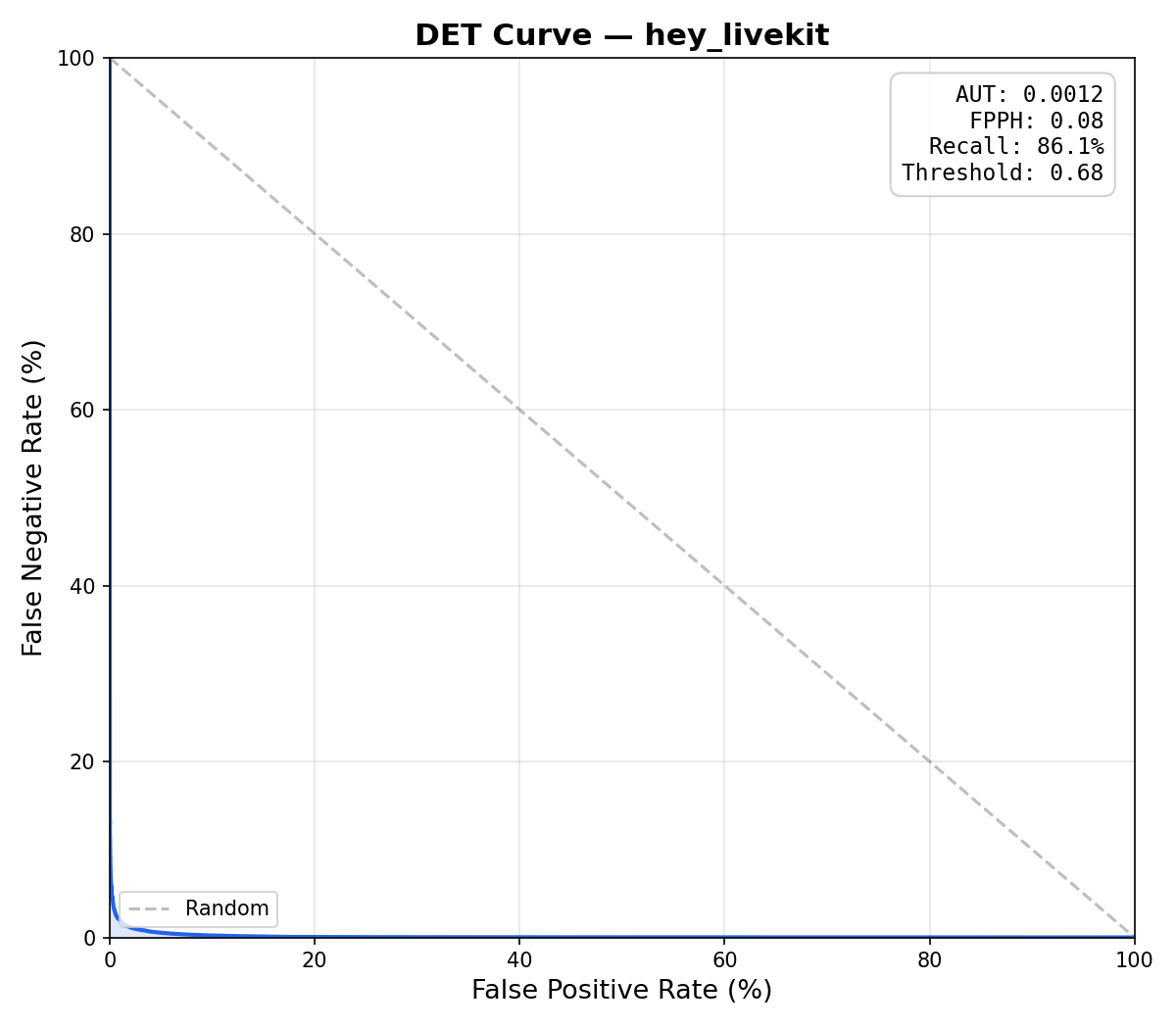
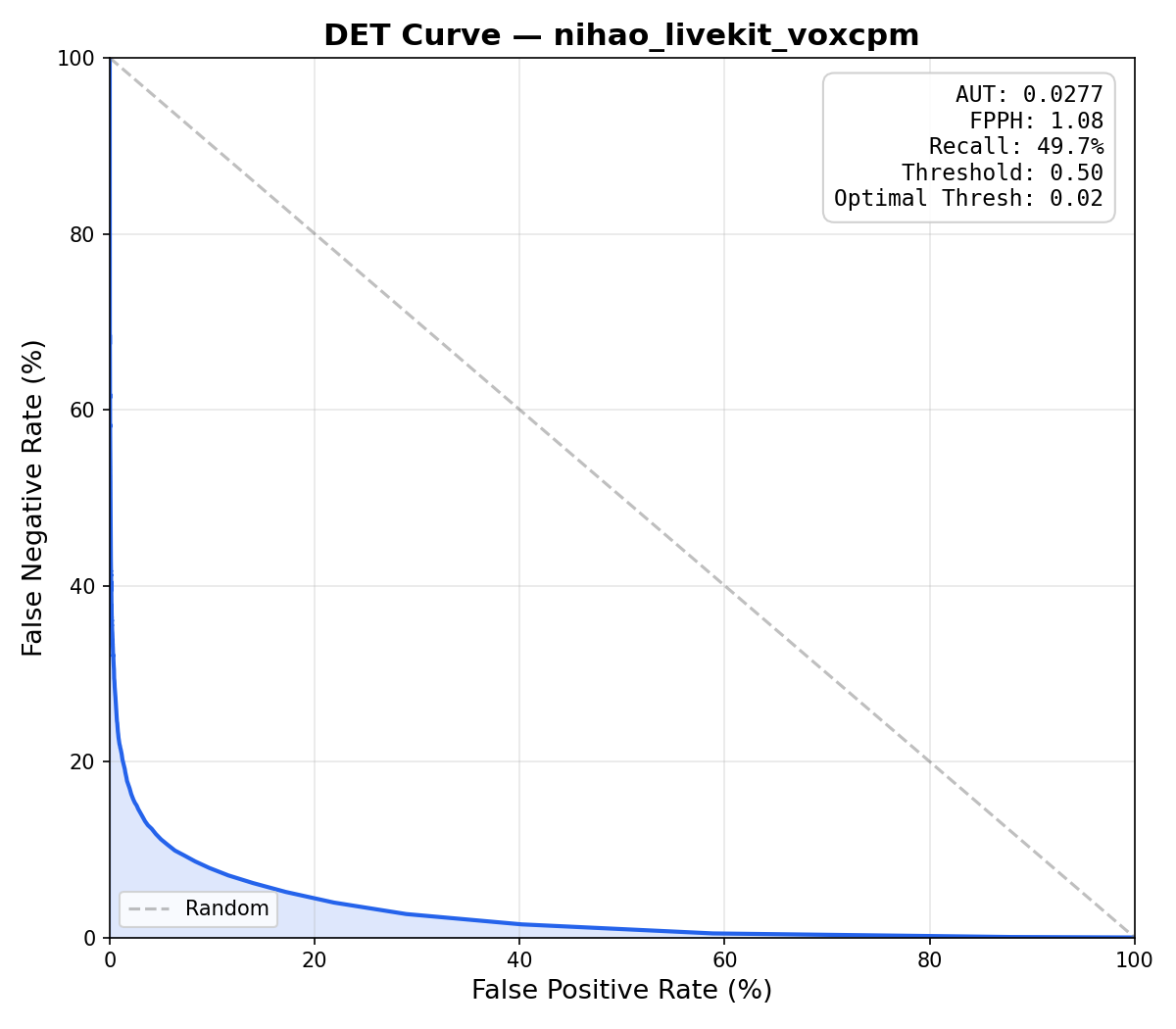
Features
- Conv-Attention classifier — 1D Conv blocks + MultiheadAttention + MeanPool head that models temporal ordering of phoneme embeddings; 60× lower AUT than openWakeWord.
- Backward compatible with openWakeWord models and the openWakeWord library interface.
- Multilingual training — 30 languages plus 9 Chinese dialects via VoxCPM2 synthetic TTS; English uses Piper VITS with SLERP speaker blending.
- Three classifier architectures — DNN (flat FC), RNN (bi-LSTM), Conv+Attention (default); four size presets (tiny / small / medium / large).
- Single-YAML pipeline — one config file drives data generation, augmentation, feature extraction, 3-phase training, ONNX export, and DET-curve evaluation.
- Synthetic training data — adversarial negatives via CMU-dict phoneme substitution; no real audio recordings required.
- 3-phase adaptive training — focal loss + embedding mixup + checkpoint averaging to minimize FPPH while maximizing recall.
- INT8 quantization — optional ONNX INT8 quantization via
--quantizeexport flag. - Python inference API —
WakeWordModel(stateless predict) +WakeWordListener(async microphone capture with debouncing). - Rust crate — mel and embedding models compiled into binary; only classifier ONNX loaded at runtime; automatic resampling from 22050–384000 Hz.
- Swift package — iOS 16+ / macOS 14+; ONNX Runtime with CoreML Execution Provider dispatches to ANE/GPU/CPU;
AVAudioConverterhandles mic resampling. - Cloud GPU training — SkyPilot integration dispatches training jobs to cloud providers (Nebius example included).
- DET curve evaluation — AUT, FPPH, and recall metrics; evaluates any compatible ONNX model including openWakeWord models.
- uv-native — zero dependency-conflict setup via
uv sync --all-extras.
Live examples
- iOS/macOS SwiftUI demo — runnable SwiftUI app for iOS + macOS using WakeWordListener with microphone capture.
- Wake Word–Triggered Agent — full LiveKit agent that starts a voice session on wake word detection.
Documentation
- Architecture Overview
- Data Generation
- Augmentation
- Feature Extraction
- Training
- Export & Inference
- Evaluation
Quick start
# Install (inference only)
pip install livekit-wakeword[listener]
# Install (full training pipeline)
pip install livekit-wakeword[train,eval,export]
# Download models and training data
livekit-wakeword setup --config configs/prod.yaml
# Train a custom wake word end-to-end
livekit-wakeword run configs/prod.yaml
Documentation
8 pages indexed · 1,169 wordsREADMElivekit-wakeword — Wake Word Librarygithub.com/livekit/livekit-wakeword/blob/main/README.md
Architecture Overviewgithub.com/livekit/livekit-wakeword/blob/main/docs/overview.md
Export & Inference APIgithub.com/livekit/livekit-wakeword/blob/main/docs/export-and-inference.md
Training Pipelinegithub.com/livekit/livekit-wakeword/blob/main/docs/training.md
Data Generation Pipelinegithub.com/livekit/livekit-wakeword/blob/main/docs/data-generation.md
Augmentation Pipelinegithub.com/livekit/livekit-wakeword/blob/main/docs/augmentation.md
Feature Extraction Pipelinegithub.com/livekit/livekit-wakeword/blob/main/docs/feature-extraction.md
Evaluation — DET curves, AUT, FPPHgithub.com/livekit/livekit-wakeword/blob/main/docs/evaluation.md